NVIDIA Democratizes Supercomputing
DGX Spark Brings the Data Center to the Desktop. What does that mean for the future of Tech & AI?

Over 150 subscribers have joined in the last 30 days. Thank you! You keep me interested and motivated to write 🙏
Outline
NVIDIA DGX Spark
What is it, how much does it cost
Democratized supercomputing
Compound innovation
Hyper-Specialized AI
Industry, Organizations, Personalization
Dual-System Workstations
Traditional, Current, Future Paradigms
Tune locally, scale in cloud
Small models just got Bigger
Distinguishing between Personal and Mobile models
Conclusion

NVIDIA DGX Spark
On March 18, 2025 Nvidia announced the DGX Spark (formerly known as Project DIGITS), a personal supercomputer capable of 1,000 trillion operations per second (TOPS). The DGX Spark can run AI models of up to 200 billion parameters and, when paired with another DGX Spark, can together run AI models of up to 405 billion parameters.
This means that you could locally run GPT 3 (175B parameters), Claude 3.5 Sonnet (~175B parameters), or… more interestingly, one of the open source models like DeepSeek R1 (145B parameters) or Llama 3.3 (70B parameters).
Again… running these models locally. This is a big deal, and I explore why in more detail below.
How much is it?
It is definitely a prosumer product, rather than a consumer product. It‘s expected to sell for $3,000-$4,000 (I’ve seen a few different reports on the price point). I wouldn’t expect every household to have a DGX by the end of the year, but in a world where professional developers commonly spend ~$2,000 on a new laptop… the DGX price point feels within reach for lots of people who work in tech.
It’s also quite small, which is nice. It looks a bit like an oversized coaster. There’s almost certainly room on your desk for one of these supercomputers if you want one.

Democratized AI Supercomputing
What happens when supercomputing power, traditionally reserved for research labs and data centers, becomes widely available to organizations, teams, and individuals? And not just available through cloud services, but available to run locally, privately, and securely.
Accelerated Innovation Cycles
We can expect innovation to accelerate. When more individuals can run extremely powerful AI models locally, the industry will experience increased volume of experimentation and novel ideas. Most experimentation today is happening in the application layer because training and fine-tuning are so often cost prohibitive for anyone who hasn’t raised hundreds of millions of dollars. But for those who make the $3,000 investment, the downstream costs of training a small model or fine-tuning a Llama model fade away.
This means we will begin to see more innovation happening at the model layer. Developers will design and train more small models (certainly less than 200B parameters), and they will be novel. They will be specialized models designed for use cases and workflows that OpenAI and Anthropic are not interested in solving because they are not along the path to AGI. And instead of having to wait for the foundation model companies to innovate, developers will be able to take the reins and drive innovation on their own, in their own way.
Below I explore some more specific ideas around how this will affect the industry.
Hyper-Specialized AI
The major players in the foundation model game (OpenAI, Anthropic, xAI, Meta, Google) are racing to AGI, artificial general intelligence. In this game bigger is better, and vast corpora of information from varied datasets is required to train these enormous models. Not to mention the capital requirements to purchase or rent racks and racks of GPUs to perform the training.
DGX Spark unlocks the opposite: small teams tinkering with small, but highly specialized datasets, to design and train niche models for use cases that the path to AGI would otherwise skip right over. This will play out at three levels:
Industry-specific models
Organization-specific models
Personalized-individual models

Industry
Imagine for a moment the vast complexity of workflows in the Health Care industry, or Manufacturing industry, or Education. How many of those workflows are context-specific? How many of those workflows are heavily dependent on private datasets that wouldn’t have been accessible to GPT, Claude, or Llama during pre-training? Hardware like DGX Spark encourages tinkering and experimentation in these niches of industry, and we’re going to see the results emerge over the next year.
Hospital-specific predictive models, supply chain optimization models for every manufacturing vertical, early identification and intervention for at-risk students. These are just a few ides that spring to mind when imagining the plethora of industry-specific models we’ll see emerge. Those with a combination of deep industry knowledge, and ML expertise will have an unfair advantage to move first on these opportunities.
Organization
Every legacy code base will be fed to locally run models to help developers ramp up quickly on unfamiliar code. Most organizations don’t do this today because they, rightly, don’t want to hand their entire codebase over to a third party. Some teams will fine-tune models to write code in a particular style, or within particular constraints necessary for their environment. Imagine a Docker image for new hires that includes a model tuned to the company’s codebase. Technical onboarding just got a lot faster.
Predictive models trained or tuned on organization-specific data will provide detailed and accurate insights into delivery timelines. Every organization works a bit differently, and those details matter when deriving insights. It won’t be enough to rely on general-use, or generic, models. Organizations that lean into training AI on their own work streams will have an unfair advantage.
Organizations may want to develop in-house language models to nudge staff and reinforce collaborative and productive communication patterns. This feels like a slippery slope that could quickly turn into a Big Brother situation. But the devil is in the design details and companies with great cultures will figure out how to deploy models like this in a manner that empowers staff rather than controls them.
Personalized
Each day, every individual generates an enormous amount of data. Overtime developers will build tools for capturing and feeding that data into locally run models for training, fine-tuning, or refinement.
We will have AI assistants that know nearly everything about our own lived experience and little about the lived experience of others. This will result in a wave of hyper-personalized models that interact just the way we need them to, and pick up on even the most subtle of our own idiosyncrasies.
So long as our data truly remains private and secure, this could be pretty cool. I for one would love to have an assistant who knows me better than I know myself and can help organize my life at the drop of a dime whenever I need it. Use cases here are vast and varied: therapy & emotional growth, personal finances, household project management, personal CRM, writing & content assistant, and on and on.
Dual-System Workstations
Marc Andreessen of a16z refers to LLMs as a new operating system. The DGX Spark reinforces and brings this metaphor to life. As Jensen Huang recently stated in his GTC keynote, “in the future, every developer will be AI assisted.” I know this will be true. If you follow my work, you know I write a lot about prompt driven development. AI isn’t replacing developers, it’s giving them super powers.
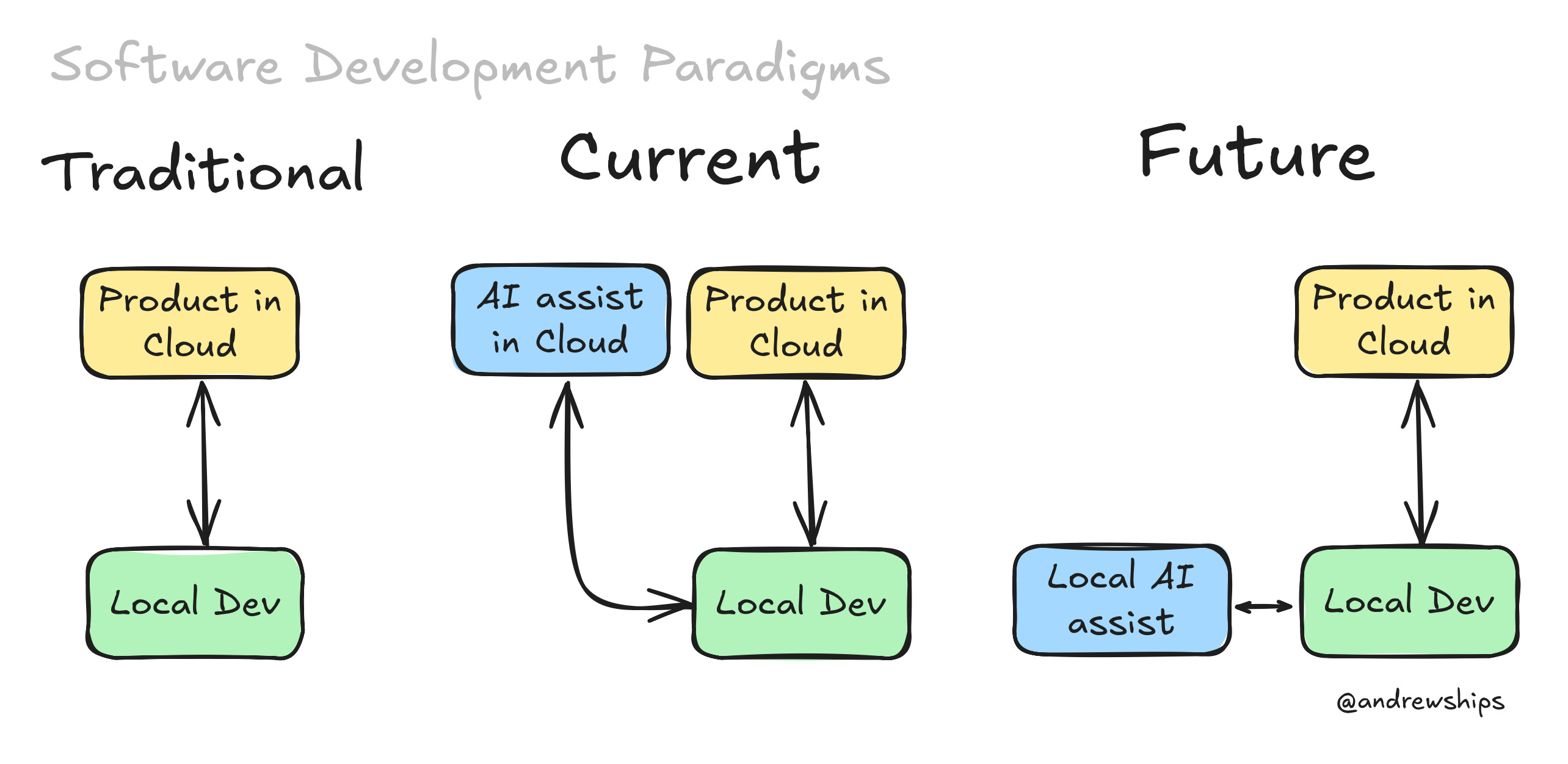
Let’s look at the traditional, current, and future software development paradigms from a high-level, AI-assisted perspective.
Traditional Paradigm
No AI assistance. Software is developed locally by individuals and teams of developers. The share code lives in a repository in the cloud. The code is deployed to a cloud hosting provider where the product is made available to users.
Current Paradigm
AI assistance in the cloud. Software is developed locally. Developers use AI systems that live in the cloud to assist their development practices. The code repository and product both live in the cloud.
Future Paradigm
AI assistance goes local. Software is developed locally. Developers use AI systems that live in a DGX Spark (or equivalent hardware) on their physical desk. The repository and product both live in the cloud.
Tune locally, scale in Cloud
This new paradigm will extend into AI model development as well. In a world where developers have their own personal super computers on their desk, AI model development can look more and more like traditional web development. Developers will prototype and iterate on model development locally, and then deploy finalized models to larger infrastructure for production use.
If you follow me on TikTok, you may recall my prediction in January that the DGX Spark could eat into cloud hosting markets a bit, because the dependency on cloud-hosted AI assistance would decrease. I think I had this wrong, Jensen Huang convinced me otherwise. Instead, the DGX Spark drives more cloud-hosting demand because it results in more model development and, therefore, more need for hosting those models in the cloud.
Nvidia is indeed providing tooling for this workflow specifically. The idea is that developers using a DGX Spark can seamlessly deploy their models to DGX Cloud when they are ready to make it available to a larger audience.
Small models just got Bigger
Mobile vs. Personal Models
The dual trend of general-use models growing in size, while specialized models shrink in size has been going on for a few years. The line in the sand between “big” and “small” models is drawn by the hardware that can run them. Recently, this line has been drawn by personal computers and mobile devices. Models that are small enough to run on these devices, and still add specialized value, can be considered viable small models to deploy on edge. Meanwhile, any model not able to be run on edge is effectively limited in size only by the capital available to purchase GPUs at scale and house them in a data center.
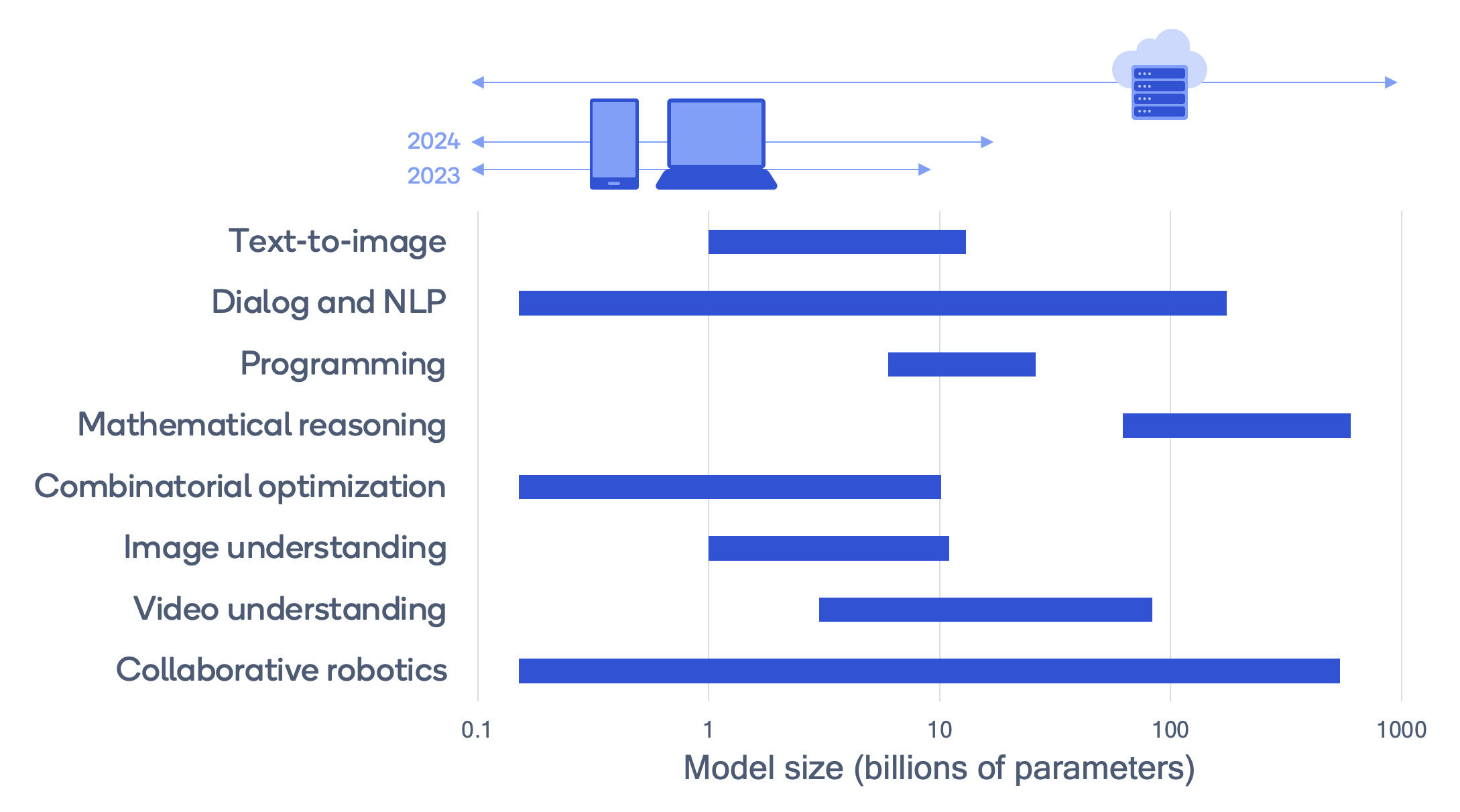
Modern laptops and mobile devices can run models anywhere from 1 billion to maybe up to 20 billion parameters in size, and that would be pushing it. The introduction of DGX Spark pushes the “small model” size up to 200 billion parameters, allowing us to run models of this size on personal devices, locally, at home.
This will influence how model designers think about parameter count. And a new class of model will emerge: the “Personal Model”. What we now consider small models will be broken into two categories: mobile and personal. Mobile models are those you can easily take with you and run on a phone or laptop. Personal are those you can run at home.

Although the DGX Spark, and similar devices, will initially be owned by developers, the desire to run sophisticated models at home will become more common overtime. Model designers will need to keep these breakpoints in mind as they develop models for particular use cases. I’m excited to watch as the Personal Model category gets filled with interesting and novel solutions.
Conclusion
The Nvidia DGX Spark marks an early move in the long-term democratization of supercomputing power. This will result in large scale, rapid innovation within AI model development. Industries, organizations, and individuals will enjoy hyper-specialized models. Developers will build with local, private AI assistants on their home desk. A new class of model, the “Personal Model” will open up doors for local, private, at home use cases of sophisticated models not previously available.
I’m excited for the future. How about you?
The real question is — can it run Crysis?
Big one!! Hope you also like this video that I generated: https://app.symvol.io/videos/nvidia-democratizes-supercomputing-1403